CrowdStrike Falcon® Data Protection
Stop data theft
The industry’s only unified platform for data protection and endpoint security.
Traditional data protection fails to stop breaches
IBM Cost of Data Breach Report
$4.45M
average cost of a breach1
Verizon Data Breach Investigation Report
74%
of all breaches include the human element2
CSA Data Loss Prevention Report
1/3
organizations struggle to manage their complex DLP environments3
MMR Group trusts CrowdStrike to protect their data
“Our old endpoint DLP solution made us navigate different consoles to dig out the data egress incidents and connect the dots manually. CrowdStrike’s unified platform approach made it super-easy for us to navigate from endpoint incidents to data protection incidents, within the same console to detect unauthorized data exfiltration.”

A modern approach to effortlessly stop data theft
The industry’s only unified platform for data protection built on a unified agent and single console.
Protect data instantly
Achieve rapid, frictionless deployment at scale with our single, lightweight agent. Roll out to thousands of endpoints in hours, no reboots required.
Get instant visibility into data flows, with near-zero configurations, to understand both the known and unknown egresses.
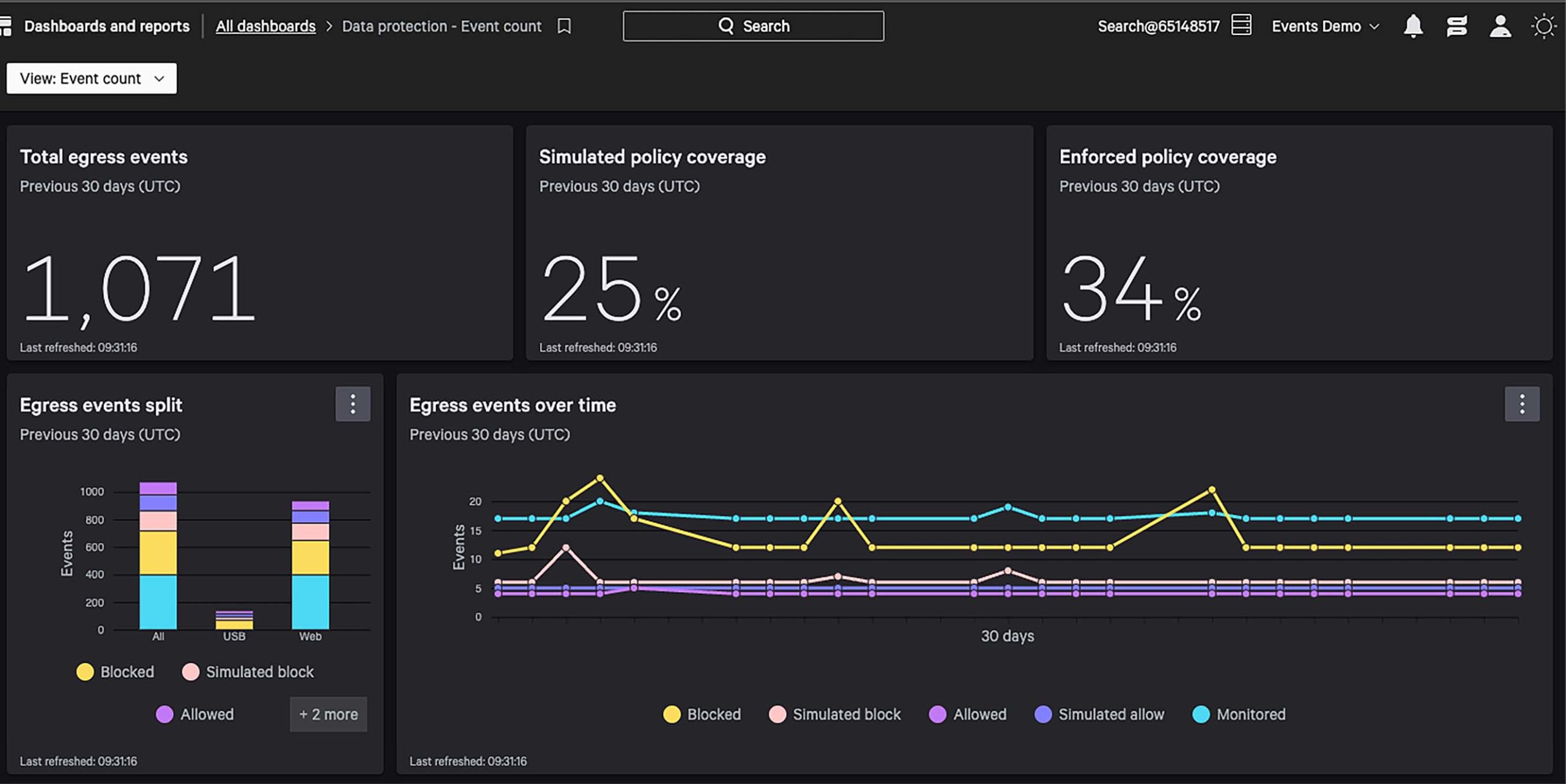
Operationalize with zero disruptions.
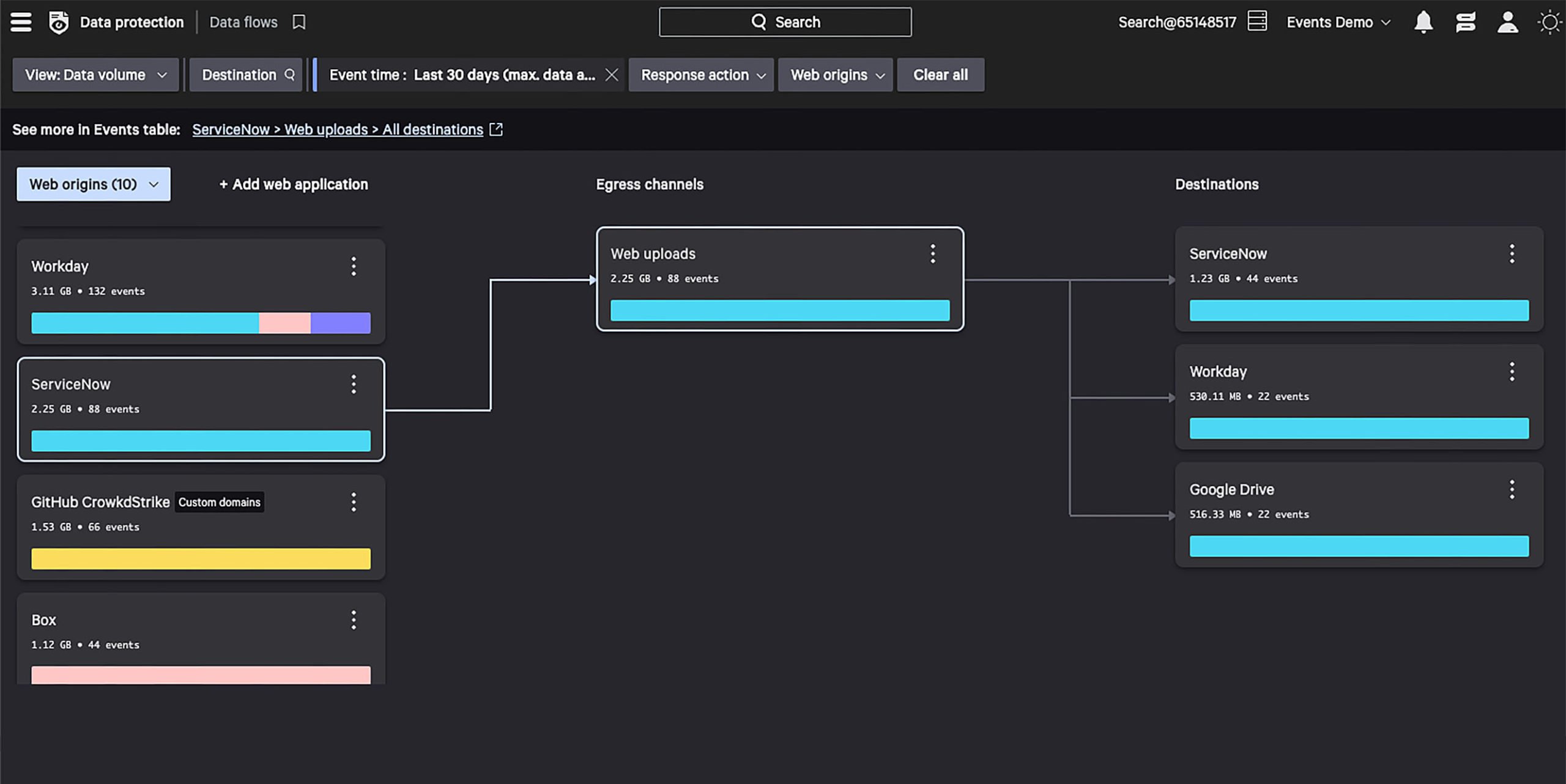
Get instant visibility into sensitive data flows.
Precisely detect sensitive data
Easily define nuanced data classifications based on content patterns, web sources, and more to accurately detect data theft.
Reliably detect and prevent the movement of sensitive data by combining both content and context across endpoints, identities, data, and egress channels.
Stay compliant and ensure security control with minimal configuration to detect and prevent sensitive PCI, PHI, PII data leakage.
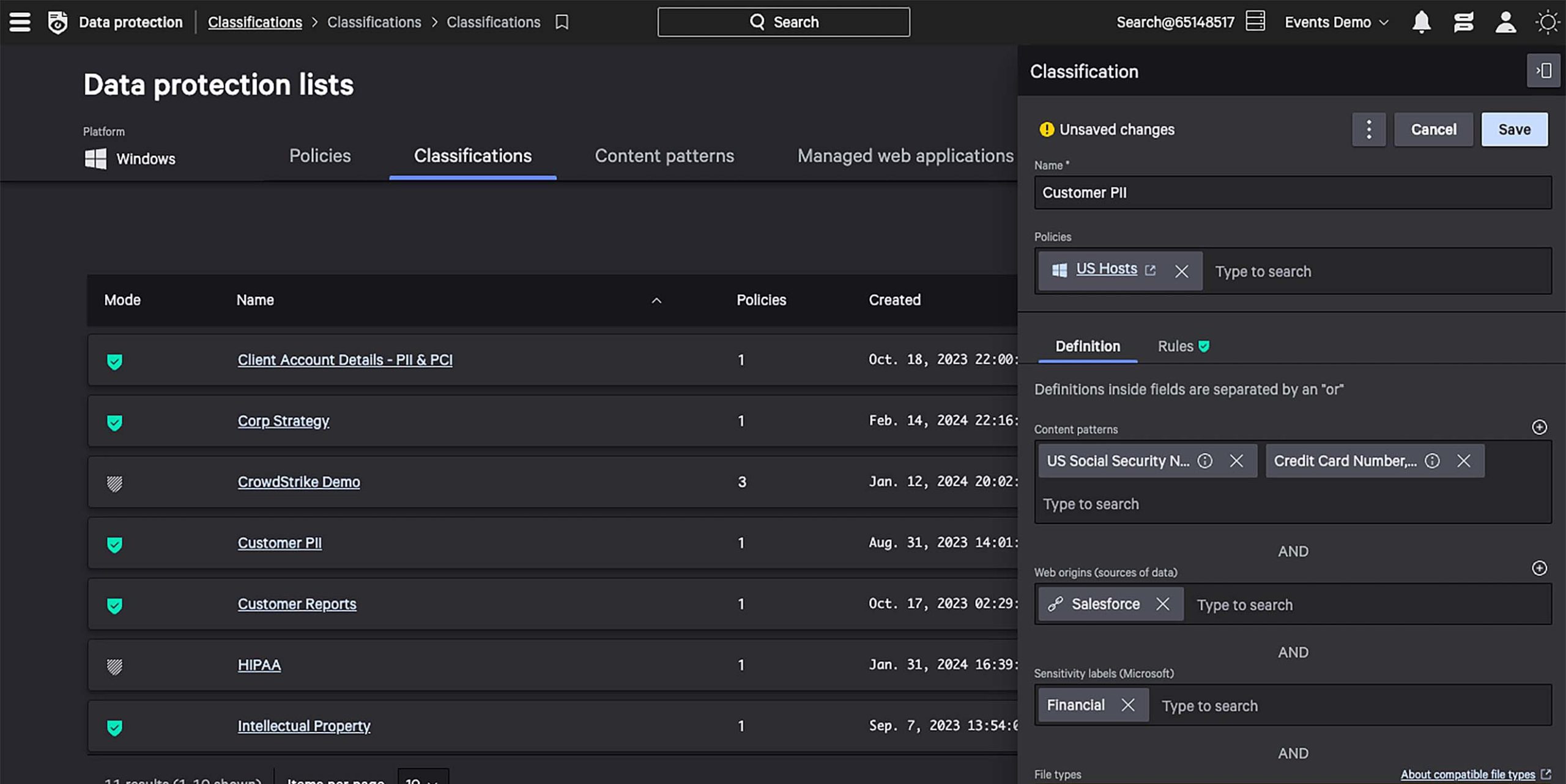
Define custom data classifications.
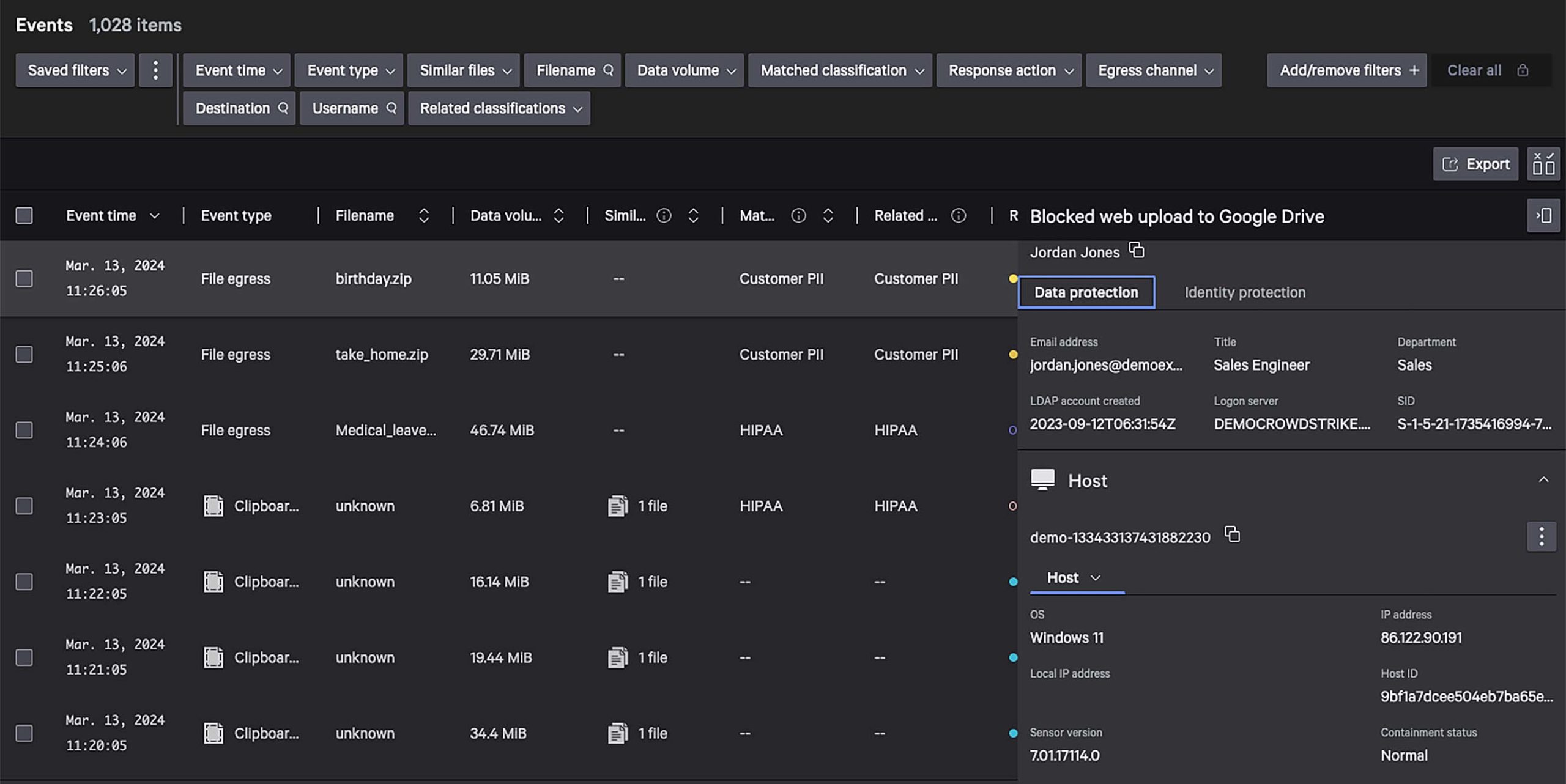
Get contextual visibility across endpoints, identities, and data.
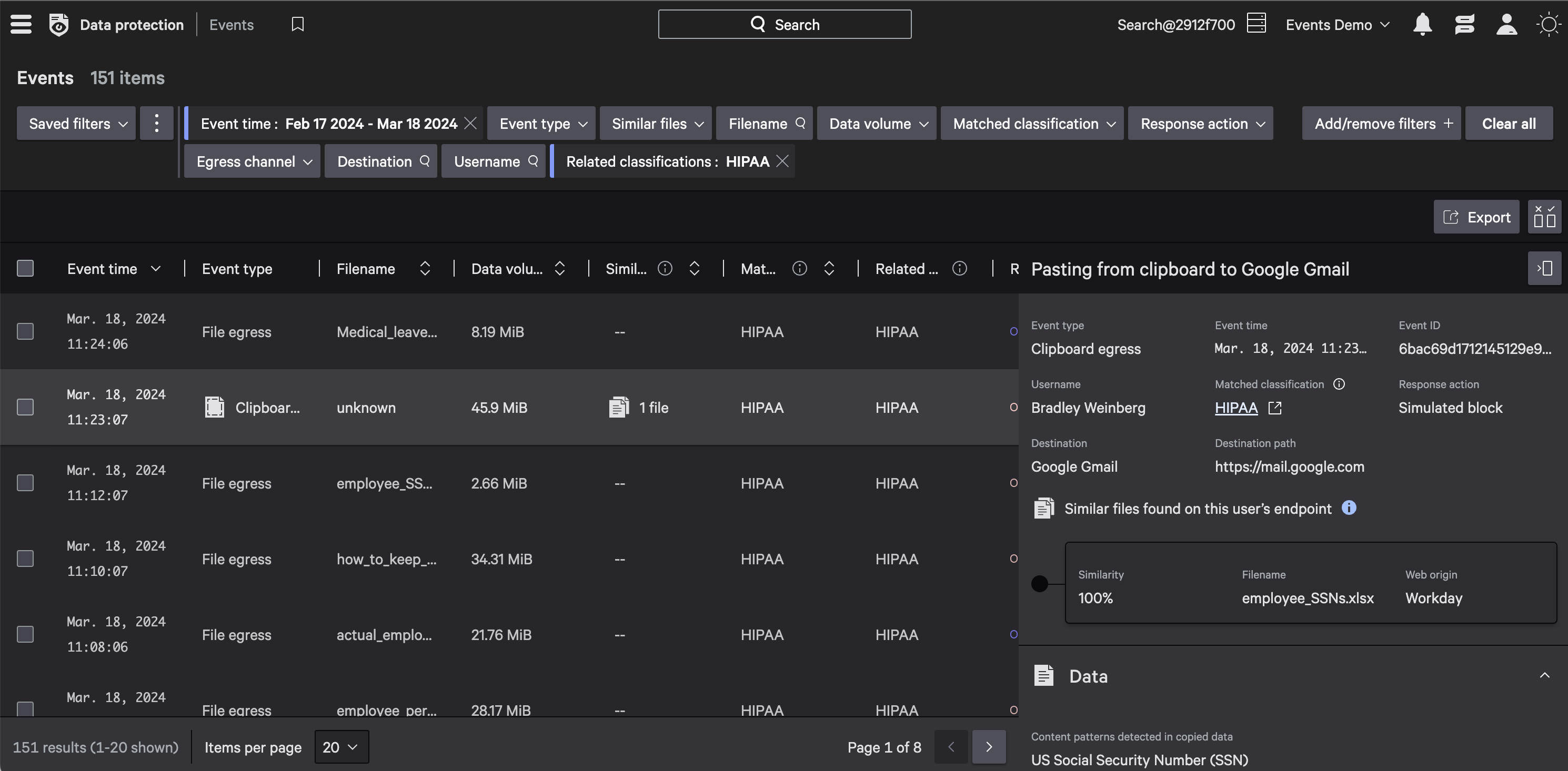
Detect and stop compliance violations.
Stop data theft with ease
Simulate “what-if” scenarios and confidently enforce ‘block’ rules to stop data theft without disrupting the end-user experience and productivity.
Uncover similar files on your endpoint and trace sensitive data back to its origin for policy enforcement, even if it’s been copied, zipped, or renamed.
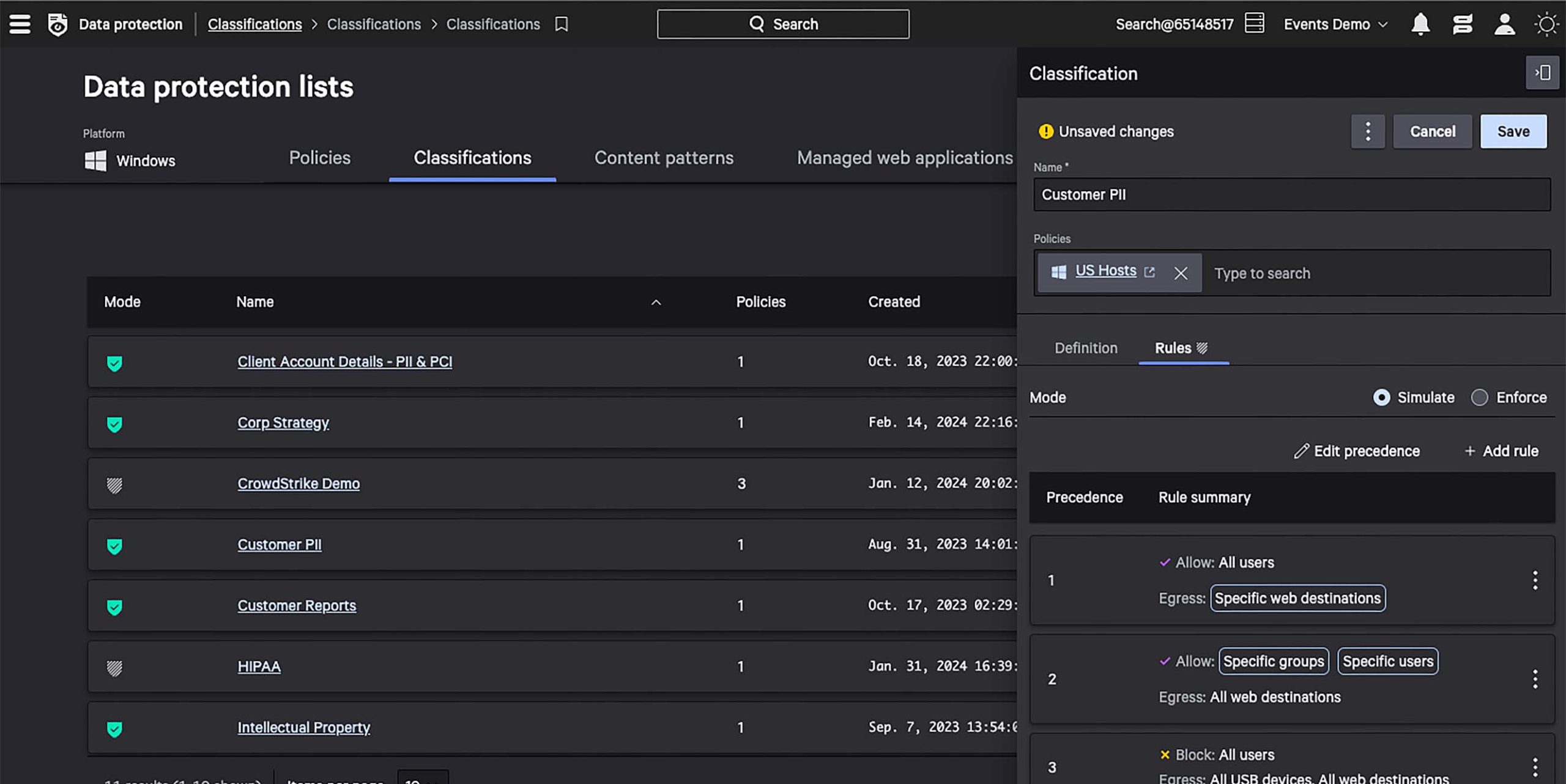
Simulate rules without disrupting productivity.
Fine tune inspection settings for increased detection accuracy.
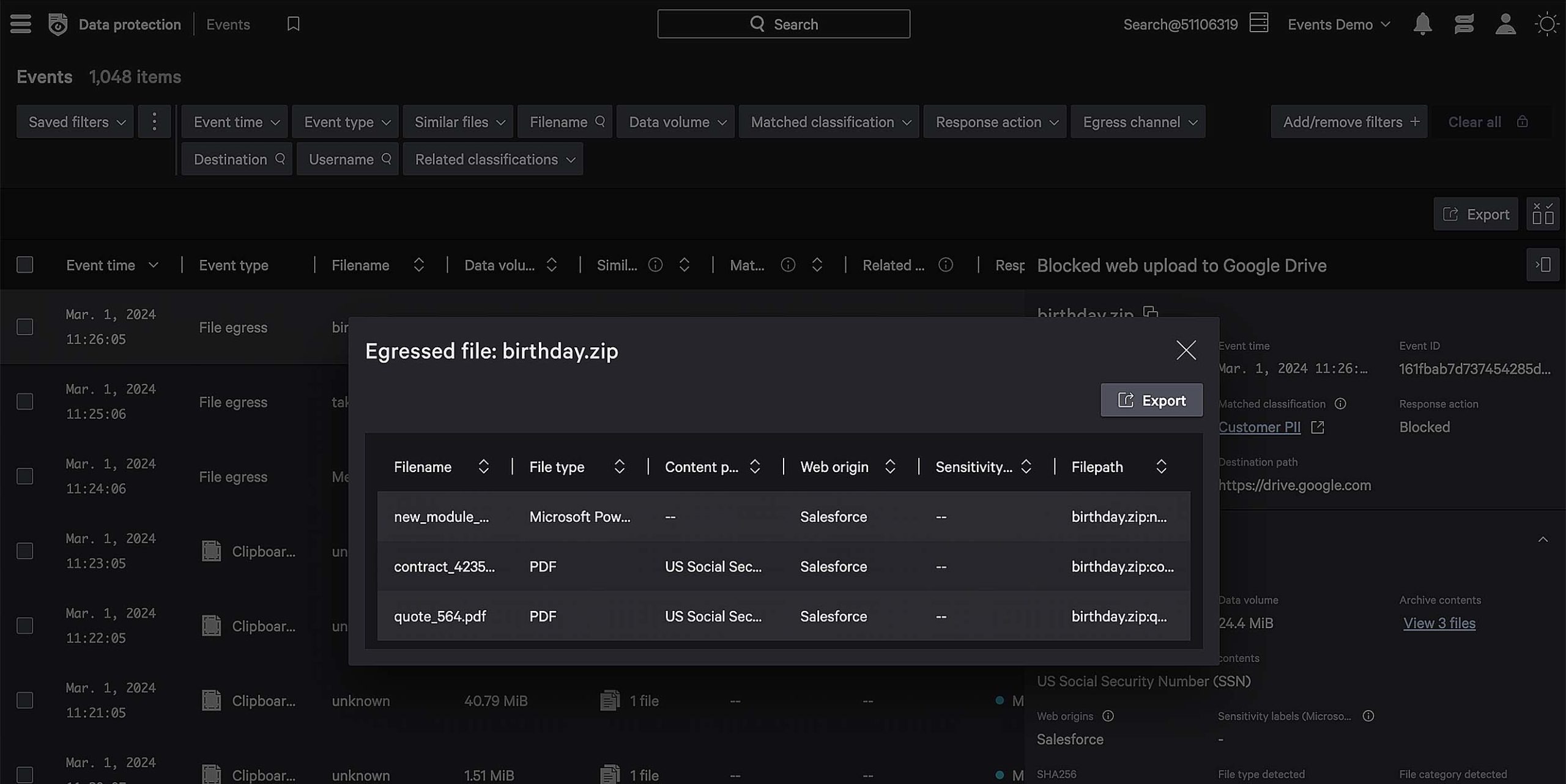
Trace file derivatives back to its original source.
See the power of Falcon Data Protection in under three minutes

Related products

CrowdStrike Falcon® Insight XDR
Falcon Insight XDR delivers detection, investigation, and response to ensure nothing is missed and breaches are stopped.

CrowdStrike Falcon® Identity Protection
The industry’s only unified platform for identity threat detection and response (ITDR) and endpoint security.

CrowdStrike Falcon® Exposure Management
The world’s leading AI-powered platform for exposure management.
Featured resources



1 Results are from IBM Cost of Data Breach Report. Individual results may vary.
2 Results are from Verizon Data Breach Investigations Report. Individual results may vary.
3 Results are from CSA Data Loss Prevention and Data Security Survey Report. Individual results may vary.